经过一段时间的Coding,实现了一个爬取网站信息的项目,在部署到服务器之前,需要进行打包发布 , 目标平台 Windows
使用pyinstallesr 进行发布
安装 pyinstaller
pip install pyinstaller
使用命令打包文件
pyinstaller -D autorun.py 打包为文件夹发布 或者 pyinstaller -F autorun.py 打包为单exe文件发布. pyinstaller会增加如下两个文件夹 (ps:严格区分大小写, -d 或者-f 的话 它不甩你)
运行打包后的exe文件
然而把大象装冰箱,并不是理想的三步完成, 在打包 Scrapy 爬虫工具软件时,还需要额外的工作
已实测不可打包成单exe文件运行 ,所有必须使用 -D 命令 进行打包
在 .py文件中需要指明 该项目所有引用的包文件
需要先将 爬虫的其实文件中加入 引用的库 ,打包时会根据清单从现有环境中进行索取打包,需要的清单有
scrapy.crawler CrawlerProcess scrapy.utils.project get_project_settings urllib.robotparser scrapy.spiderloader scrapy.statscollectors scrapy.logformatter scrapy.dupefilters scrapy.squeues scrapy.extensions.spiderstate scrapy.extensions.corestats scrapy.extensions.telnet scrapy.extensions.logstats scrapy.extensions.memusage scrapy.extensions.memdebug scrapy.extensions.feedexport scrapy.extensions.closespider scrapy.extensions.debug scrapy.extensions.httpcache scrapy.extensions.statsmailer scrapy.extensions.throttle scrapy.core.scheduler scrapy.core.engine scrapy.core.scraper scrapy.core.spidermw scrapy.core.downloader scrapy.downloadermiddlewares.stats scrapy.downloadermiddlewares.httpcache scrapy.downloadermiddlewares.cookies scrapy.downloadermiddlewares.useragent scrapy.downloadermiddlewares.httpproxy scrapy.downloadermiddlewares.ajaxcrawl scrapy.downloadermiddlewares.decompression scrapy.downloadermiddlewares.defaultheaders scrapy.downloadermiddlewares.downloadtimeout scrapy.downloadermiddlewares.httpauth scrapy.downloadermiddlewares.httpcompression scrapy.downloadermiddlewares.redirect scrapy.downloadermiddlewares.retry scrapy.downloadermiddlewares.robotstxt scrapy.spidermiddlewares.depth scrapy.spidermiddlewares.httperror scrapy.spidermiddlewares.offsite scrapy.spidermiddlewares.referer scrapy.spidermiddlewares.urllength scrapy.pipelines scrapy.core.downloader.handlers.http scrapy.core.downloader.contextfactory scrapy.core.downloader.handlers.ftp scrapy.core.downloader.handlers.file scrapy.core.downloader.handlers.datauri scrapy.core.downloader.handlers.s3 time dbwriter
增加上述引入后 ,重复进行第二步.
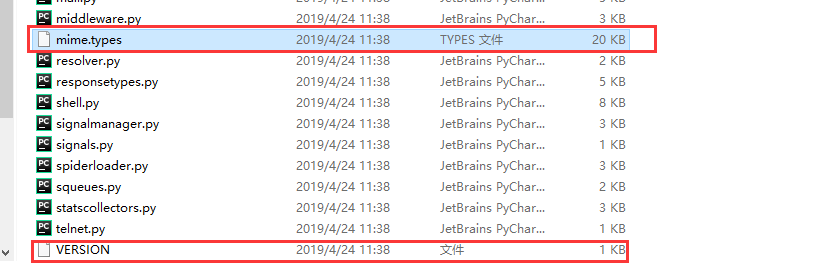
现在再解决打包后 出现找不到 Scrapy 的Version文件问题
此时需要去Scrapy 的安装目录下 找到对应的两个文件复制到 打包dist\[autorun]\的文件下. autorun为步骤2中的 .py文件名
Anaconda3\pkgs\scrapy-1.6.0-py37_0\Lib\site-packages\scrapy (使用的是Anaconda环境)
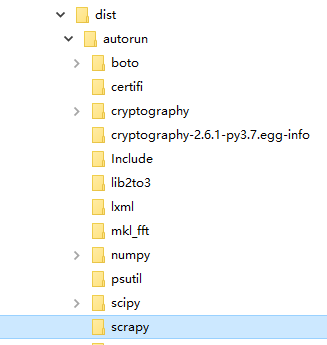
如此,便可大概率正常运行, 如果运行提示缺失Model , 就在 .py文件中 补充import 重复 第2 ,3 步
写在最后,为了快速复制 scrapy 的文件到 打包后的文件中 补充了解了 xcopy 使用
xcopy F:\PyWorkplace\scrapy F:\PyWorkplace\PyMaQuery\maSpiderDemo\trunk\maSpiderDemo\dist\autorun\scrapy /e /y /i
